










У 2016 році, виступаючи на Всесвітньому економічному форумі в Давосі, його президент Клаус Мартін Шваб говорив про «Четверту промислову революцію»: нову еру тотальної автоматизації, яка породжує конкуренцію між людським інтелектом і штучним інтелектом. Цю промову (як і однойменну книгу) вважають переломним моментом у розвитку нових технологій. Багатьом країнам довелося вибрати, яким шляхом вони підуть: пріоритет технологій над правами і свободами особистості чи навпаки? Так технологічний перелом перетворився на соціальний і політичний.
Про що ще говорив Шваб і чому це так важливо?
Революція змінить баланс сил між людьми та машинами: штучний інтелект (ШІ) та роботи створять нові професії, але також знищать старі. Все це породить соціальну нерівність та інші потрясіння в суспільстві.
Цифрові технології дадуть величезну перевагу тим, хто з часом зробить на них ставку: винахідникам, акціонерам та венчурним інвесторам. Те ж саме стосується і штатів.
Сьогодні в змаганнях за світове лідерство перемагає той, хто має найбільший вплив у сфері штучного інтелекту. Глобальний прибуток від застосування технології штучного інтелекту в найближчі п'ять років оцінюється в 16 трильйонів доларів, а бНайбільша частка припадатиме на США та Китай.
У своїй книзі «Надсилові можливості штучного інтелекту» китайський ІТ-експерт Кай-Фу Лі пише про боротьбу між Китаєм і США в галузі технологій, феномен Кремнієвої долини та колосальну різницю між двома країнами.
США і Китай: гонка озброєнь
USA вважається однією з найрозвиненіших країн у сфері штучного інтелекту. Глобальні гіганти з Силіконової долини, такі як Google, Apple, Facebook або Microsoft, приділяють велику увагу цим розробкам. До них приєднуються десятки стартапів.
У 2019 році Дональд Трамп доручив створити American AI Initiative. Він працює в п'яти напрямках:
Стратегія штучного інтелекту Міністерства оборони США розповідає про використання цих технологій для військових потреб і кібербезпеки. При цьому ще в 2019 році США визнали перевагу Китаю за деякими показниками, пов’язаними з дослідженнями ШІ.
У 2019 році уряд США виділив близько $1 млрд на дослідження в галузі штучного інтелекту. Однак до 2020 року лише 4% генеральних директорів США планують запровадити технологію ШІ, порівняно з 20% у 2019 році. Вони вважають, що можливі ризики технології набагато вищі за її можливості.
Китай прагне обігнати США в області штучного інтелекту та інших технологій. Точкою відліку можна вважати 2017 рік, коли з’явилася Національна стратегія розвитку технологій ШІ. Згідно з нею, до 2020 року Китай повинен був наздогнати світових лідерів у цій сфері, а загальний ринок штучного інтелекту в країні повинен був перевищити 22 мільярди доларів. Вони планують інвестувати 700 мільярдів доларів у розумне виробництво, медицину, міста, сільське господарство та оборону.
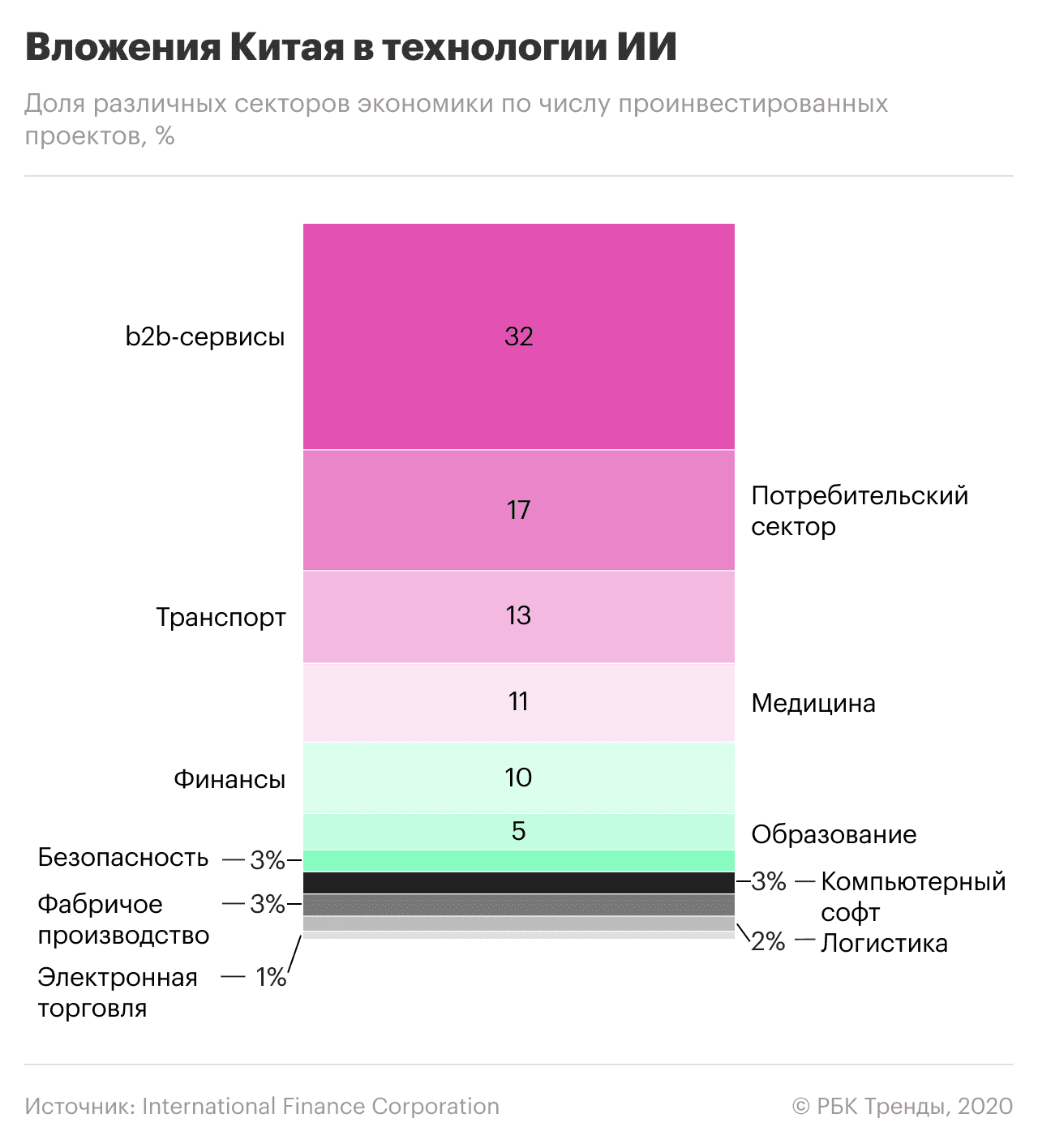
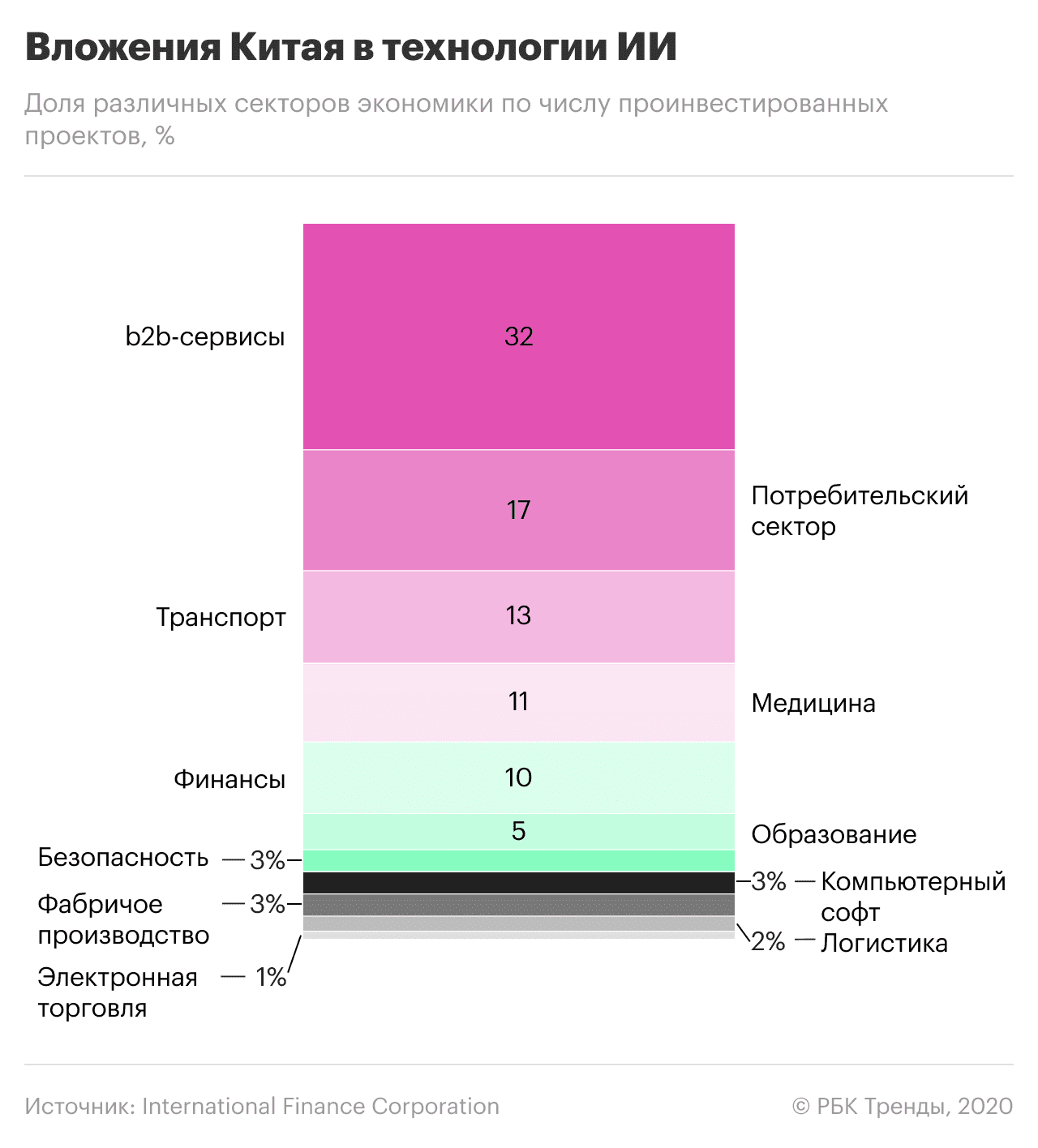
Лідер Китаю Сі Цзіньпін вважає ШІ «рушійною силою технологічної революції» та економічного зростання. Екс-президент китайської Google Лі Кайфу пов'язує це з тим, що AlphaGo (розробка головного офісу Google) перемогла китайського чемпіона з гри го Ке Цзе. Це стало технологічним викликом для Китаю.
Головне, в чому країна поки що поступалася США та іншим лідерам, — це фундаментальні теоретичні дослідження, розробка базових алгоритмів і чіпів на основі ШІ. Щоб подолати це, Китай активно запозичує найкращі технології та спеціалістів зі світового ринку, не допускаючи при цьому іноземних компаній конкурувати з китайськими на внутрішньому ринку.
При цьому серед усіх компаній у сфері штучного інтелекту в кілька етапів відбираються найкращі та висуваються до лідерів галузі. Подібний підхід вже застосовувався в галузі телекомунікацій. У 2019 році в Шанхаї почали будувати першу пілотну зону з інновацій і застосування штучного інтелекту.
У 2020 році уряд обіцяє виділити ще 1,4 трильйона доларів на 5G, штучний інтелект та безпілотні автомобілі. Вони роблять ставку на найбільших постачальників хмарних обчислень і аналізу даних – Alibaba Group Holding і Tencent Holdings.
Baidu, «китайський Google» з точністю розпізнавання обличчя до 99%, стартапи iFlytek і Face були найуспішнішими. Ринок китайських мікросхем тільки за рік – з 2018 по 2019 рік – виріс на 50%: до $1,73 млрд.
В умовах торговельної війни та погіршення дипломатичних відносин зі Сполученими Штатами Китай активізував інтеграцію цивільних і військових проектів у сфері ШІ. Головна мета – не лише технологічна, а й геополітична перевага над США.
Хоча Китаю вдалося обігнати Сполучені Штати в плані необмеженого доступу до великих і особистих даних, він все ще відстає в області технологічних рішень, досліджень і обладнання. У той же час китайці публікують більше цитованих статей про ШІ.
Але для того, щоб розвивати AI-проекти, нам потрібні не лише ресурси та підтримка держави. Необхідний необмежений доступ до великих даних: саме вони є основою для досліджень і розробок, а також для навчання роботів, алгоритмів і нейронних мереж.
Великі дані та громадянські свободи: яка ціна прогресу?
Великі дані в США також сприймаються серйозно та вірять у їхній потенціал для економічного розвитку. Навіть за Обами уряд запустив шість федеральних програм великих даних на загальну суму 200 мільйонів доларів.
Однак із захистом великих і персональних даних тут не все так просто. Переломним моментом стали події 11 вересня 2011 року. Вважається, що саме тоді держава надала спецслужбам необмежений доступ до персональних даних своїх громадян.
У 2007 році був прийнятий Закон про боротьбу з тероризмом. І з цього ж року в розпорядженні ФБР і ЦРУ з’явилася PRISM – один із найсучасніших сервісів, який збирає особисті дані про всіх користувачів соціальних мереж, а також сервісів Microsoft, Google, Apple, Yahoo і навіть телефонних зв’язків. записи. Саме про цю базу говорив Едвард Сноуден, який раніше працював у команді проекту.
Крім розмов і повідомлень в чатах, електронних листах, програма збирає і зберігає геолокаційні дані, історію браузера. Такі дані в США набагато менш захищені, ніж персональні дані. Усі ці дані збирають і використовують ті ж IT-гіганти з Силіконової долини.
Водночас єдиного пакету законів і заходів, що регулюють використання великих даних, досі немає. Все базується на політиці конфіденційності кожної конкретної компанії та офіційних зобов’язаннях щодо захисту даних та анонімності користувачів. Крім того, у кожному штаті є свої правила та закони щодо цього.
Деякі штати все ще намагаються захистити дані своїх громадян, принаймні від корпорацій. У Каліфорнії діє найсуворіший закон про захист даних у країні з 2020 року. Відповідно до нього користувачі Інтернету мають право знати, яку інформацію про них збирають компанії, як і навіщо вони її використовують. Будь-який користувач може вимагати його видалення або заборони збору. Роком раніше вона також заборонила використання розпізнавання облич у роботі поліції та спецслужб.
Анонімізація даних — популярний інструмент, який використовують американські компанії: коли дані анонімні, і по ним неможливо ідентифікувати конкретну особу. Однак це відкриває великі можливості для компаній збирати, аналізувати та застосовувати дані в комерційних цілях. При цьому на них більше не поширюються вимоги щодо конфіденційності. Такі дані вільно продаються через спеціальні біржі та окремих брокерів.
Проштовхуючи закони про захист від збору та продажу даних на федеральному рівні, Америка може зіткнутися з технічними проблемами, які фактично вплинуть на всіх нас. Отже, ви можете вимкнути відстеження місцезнаходження на своєму телефоні та в програмах, але як щодо супутників, які передають ці дані? Зараз їх близько 800 на орбіті, і вимкнути їх неможливо: так ми залишимося без Інтернету, зв'язку та важливих даних, включаючи зображення штормів і ураганів, що насуваються.
У Китаї з 2017 року діє закон про кібербезпеку. Він, з одного боку, забороняє інтернет-компаніям збирати та продавати інформацію про користувачів за їх згодою. У 2018 році навіть випустили специфікацію щодо захисту персональних даних, яка вважається однією з найближчих до європейського GDPR. Проте специфікація є лише зводом правил, а не законом, і не дозволяє громадянам відстоювати свої права в суді.
З іншого боку, закон вимагає від мобільних операторів, інтернет-провайдерів і стратегічних підприємств зберігати частину даних усередині країни та передавати їх владі за запитом. Щось подібне в нашій країні прописує так званий «весняний закон». При цьому контролюючі органи мають доступ до будь-якої особистої інформації: дзвінків, листів, чатів, історії браузерів, геолокації.
Загалом у Китаї діє понад 200 законів і постанов щодо захисту особистої інформації. З 2019 року всі популярні додатки для смартфонів перевіряються та блокуються, якщо вони збирають дані користувачів з порушенням закону. Під дію також потрапили ті сервіси, які формують стрічку публікацій або показують рекламу на основі вподобань користувачів. Щоб максимально обмежити доступ до інформації в мережі, в країні діє «Золотий щит», який фільтрує інтернет-трафік відповідно до законів.
З 2019 року Китай почав відмовлятися від іноземних комп’ютерів і програмного забезпечення. З 2020 року китайські компанії зобов'язані переходити на хмарні обчислення, а також надавати детальні звіти про вплив IT-обладнання на національну безпеку. Усе це на тлі торгової війни зі Сполученими Штатами, які поставили під сумнів безпеку обладнання 5G від китайських постачальників.
Така політика викликає неприйняття у світовій спільноті. У ФБР заявили, що передача даних через китайські сервери небезпечна: до них можуть отримати доступ місцеві спецслужби. Слідом за ним висловили стурбованість і міжнародні корпорації, включаючи Apple.
Всесвітня правозахисна організація Human Rights Watch зазначає, що Китай побудував «мережу тотального державного електронного стеження та складну систему інтернет-цензури». З ними погоджуються 25 держав-членів ООН.
Найяскравіший приклад – Сіньцзян, де держава контролює 13 мільйонів уйгурів, мусульманської національної меншини. Використовується розпізнавання осіб, відстеження всіх переміщень, розмов, листування та репресії. Критикують і систему «соціального кредиту», коли доступ до різноманітних послуг і навіть польотів за кордон мають лише ті, хто має достатній рейтинг благонадійності – з точки зору держслужби.
Є й інші приклади: коли держави домовляються про єдині правила, які мають максимально захищати особисті свободи та конкуренцію. Але тут, як кажуть, є свої нюанси.
Як європейський GDPR змінив спосіб збору та зберігання даних у світі
З 2018 року Європейський Союз прийняв GDPR – Загальний регламент захисту даних. Він регулює все, що стосується збору, зберігання та використання даних користувачів онлайн. Коли рік тому закон набув чинності, він вважався найжорсткішою системою захисту конфіденційності людей в Інтернеті.
Закон перераховує шість правових підстав для збору та обробки даних користувачів Інтернету: наприклад, особиста згода, юридичні зобов’язання та життєві інтереси. Існує також вісім основних прав для кожного користувача Інтернет-послуг, включаючи право отримувати інформацію про збір даних, виправляти або видаляти дані про себе.
Компанії зобов’язані збирати та зберігати мінімальну кількість даних, необхідних для надання послуг. Наприклад, інтернет-магазину не потрібно запитувати вас про ваші політичні погляди, щоб доставити продукт.
Усі персональні дані мають бути надійно захищені відповідно до норм законодавства для кожного виду діяльності. Крім того, особисті дані тут означають, серед іншого, інформацію про місцезнаходження, етнічну приналежність, релігійні переконання, файли cookie браузера.
Ще однією складною вимогою є переносимість даних з одного сервісу на інший: наприклад, Facebook може перенести ваші фотографії в Google Photos. Не всі компанії можуть дозволити собі такий варіант.
Незважаючи на те, що GDPR був прийнятий в Європі, він поширюється на всі компанії, які працюють в ЄС. GDPR поширюється на всіх, хто обробляє персональні дані громадян або резидентів ЄС або пропонує їм товари чи послуги.
Створений для захисту, для ІТ-індустрії закон обернувся найнеприємнішими наслідками. Тільки за перший рік Єврокомісія оштрафувала понад 90 компаній на загальну суму понад 56 мільйонів євро. Крім того, максимальний штраф може досягати 20 мільйонів євро.
Багато корпорацій зіткнулися з обмеженнями, які створили серйозні перешкоди для їхнього розвитку в Європі. Серед них був Facebook, а також British Airways і мережа готелів Marriott. Але в першу чергу закон вдарив по малому і середньому бізнесу: вони повинні привести всі свої продукти і внутрішні процеси під його норми.
GDPR породив цілу галузь: юридичні та консалтингові фірми, які допомагають привести програмне забезпечення та онлайн-сервіси у відповідність із законом. Його аналоги почали з'являтися в інших регіонах: Південній Кореї, Японії, Африці, Латинській Америці, Австралії, Новій Зеландії та Канаді. Документ мав великий вплив на законодавство США, нашої країни та Китаю у цій сфері.
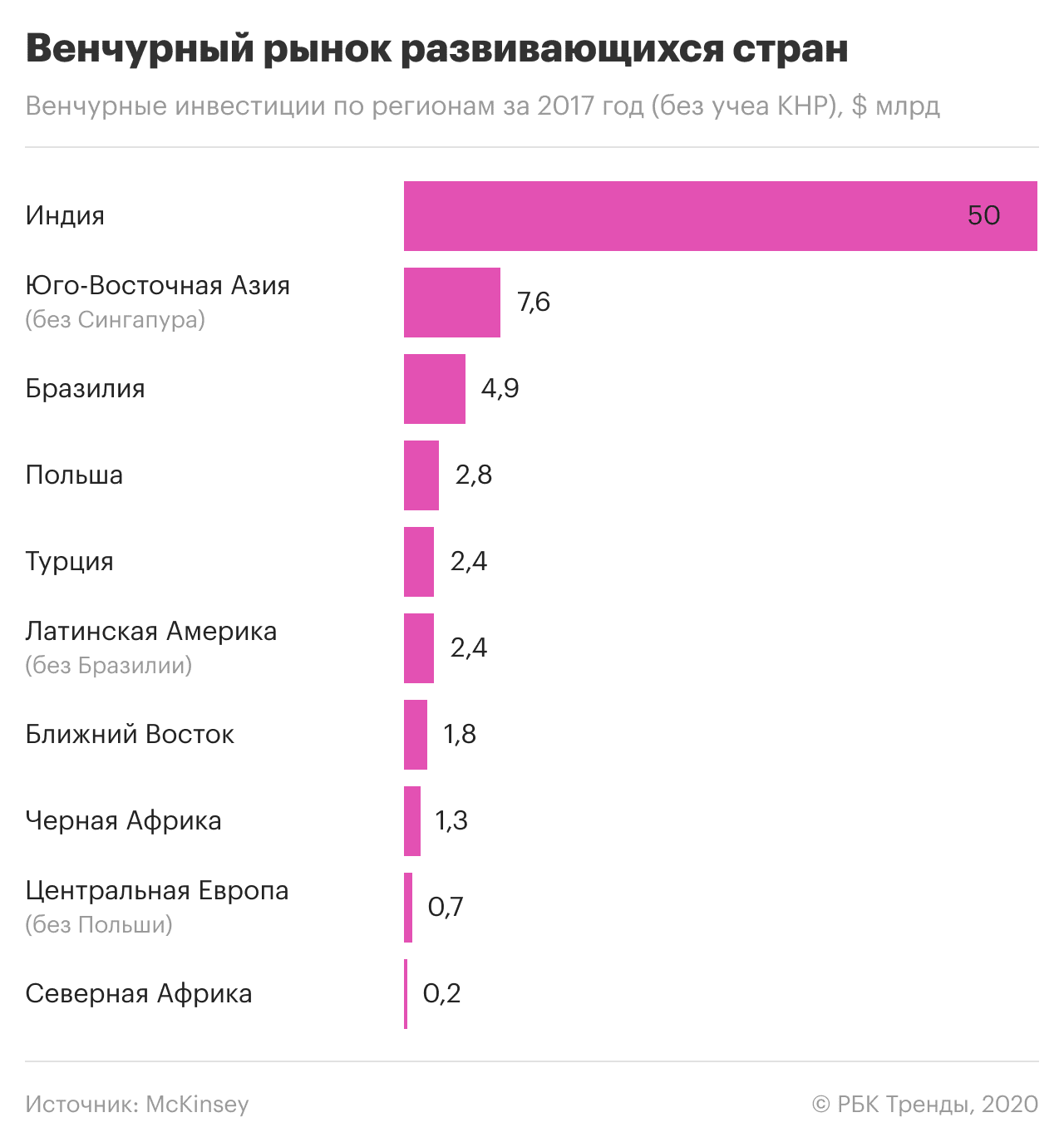
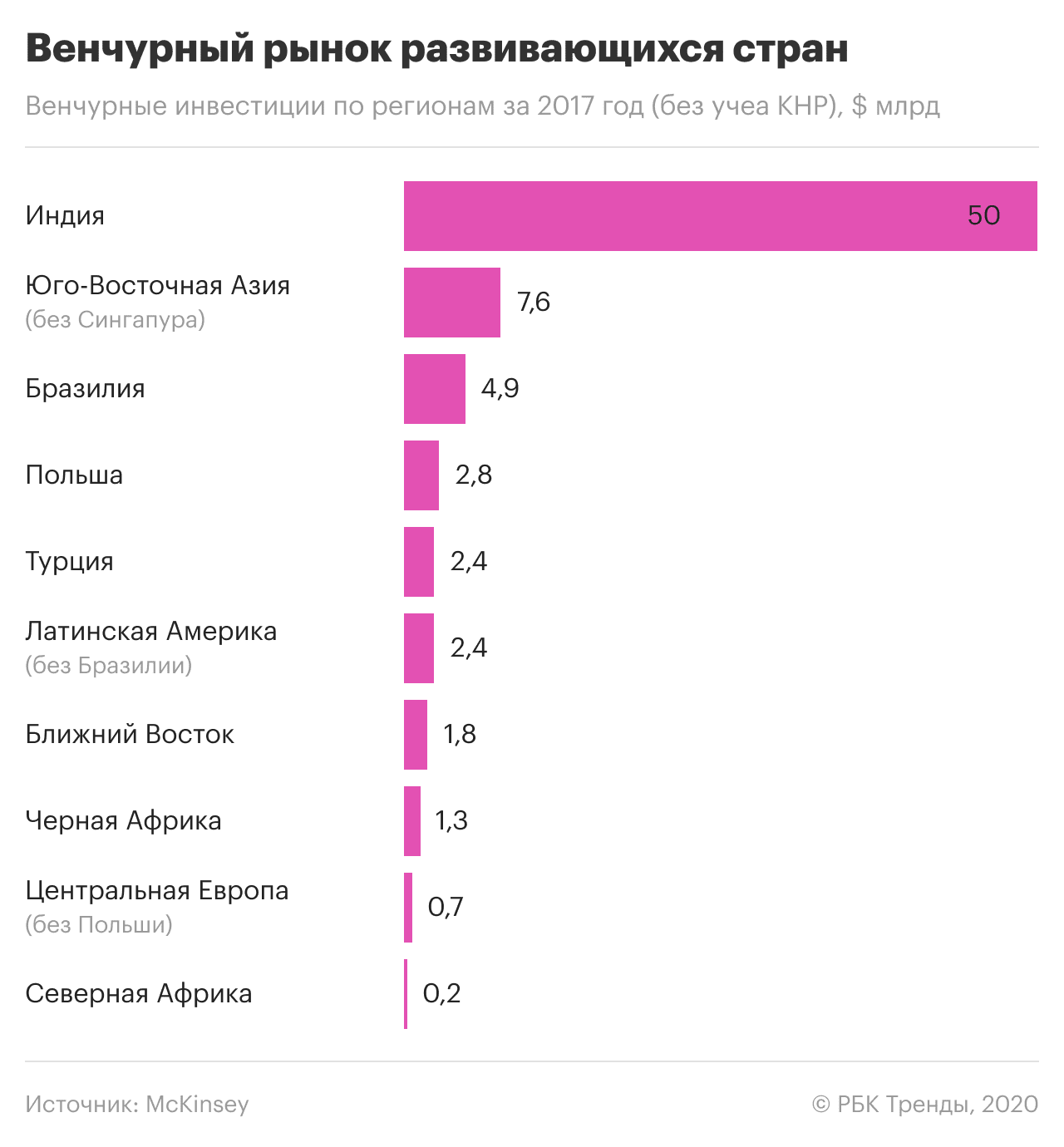
Може скластися враження, що міжнародна практика застосування та захисту технологій у сфері великих даних та ШІ складається з якихось крайнощів: тотального стеження чи тиску на ІТ-компанії, недоторканності особистої інформації чи повної беззахисності перед державою та корпораціями. Не зовсім: хороші приклади теж є.
ШІ та великі дані на службі Інтерполу
Міжнародна організація кримінальної поліції (скорочено Інтерпол) є однією з найвпливовіших у світі. До неї входять 192 країни. Одним із головних завдань організації є складання баз даних, які допомагають правоохоронним органам у всьому світі запобігати та розслідувати злочини.
Інтерпол має у своєму розпорядженні 18 міжнародних баз: про терористів, небезпечних злочинців, зброю, викрадені твори мистецтва та документи. Ці дані збираються з мільйонів різних джерел. Наприклад, глобальна цифрова бібліотека Dial-Doc дозволяє ідентифікувати вкрадені документи, а система Edison – підроблені.
Для відстеження переміщень злочинців і підозрюваних використовується передова система розпізнавання облич. Він інтегрований з базами даних, які зберігають фотографії та інші особисті дані з понад 160 країн. Його доповнює спеціальний біометричний додаток, який порівнює форми і пропорції обличчя, щоб відповідність була максимально точною.
Система розпізнавання також виявляє інші фактори, які змінюють обличчя і ускладнюють його ідентифікацію: освітлення, старіння, макіяж і грим, пластичні операції, наслідки алкоголізму і наркоманії. Щоб уникнути помилок, результати системного пошуку перевіряються вручну.
Система була запроваджена в 2016 році, і зараз Інтерпол активно працює над її вдосконаленням. Міжнародний ідентифікаційний симпозіум проводиться кожні два роки, а робоча група Face Expert двічі на рік обмінюється досвідом між країнами. Ще одна перспективна розробка – система розпізнавання голосу.
Міжнародний дослідницький інститут ООН (UNICRI) і Центр штучного інтелекту та робототехніки відповідають за новітні технології у сфері міжнародної безпеки. У Сінгапурі створено найбільший міжнародний інноваційний центр Інтерполу. Серед його розробок — робот-поліцейський, який допомагає людям на вулицях, а також технології штучного інтелекту та великих даних, які допомагають прогнозувати та запобігати злочинам.
Як ще використовуються великі дані в державних службах:
NADRA (Пакистан) – база даних мультибіометричних даних громадян, яка використовується для ефективної соціальної підтримки, податкового та прикордонного контролю.
Управління соціального забезпечення США (SSA) використовує великі дані, щоб точніше опрацьовувати заяви про інвалідність і боротися з шахраями.
Міністерство освіти США використовує системи розпізнавання тексту для обробки нормативних документів і відстеження змін у них.
FluView — американська система відстеження та контролю епідемій грипу.
Насправді великі дані та штучний інтелект допомагають нам у багатьох сферах. Вони створені на основі онлайн-сервісів, подібних до тих, що сповіщають вас про пробки чи натовпи. За допомогою великих даних та ШІ в медицині вони проводять дослідження, створюють ліки та протоколи лікування. Вони допомагають організувати міське середовище та транспорт, щоб усім було комфортно. У національному масштабі вони допомагають розвивати економіку, соціальні проекти та технічні інновації.
Ось чому питання про те, наскільки великі дані збираються та застосовуються, а також алгоритми ШІ, які з ними працюють, настільки важливі. При цьому найважливіші міжнародні документи, які регулюють цю сферу, були прийняті зовсім недавно – у 2018-19 роках. Досі немає однозначного вирішення головної дилеми, пов’язаної з використанням великих даних для безпеки. Коли, з одного боку, прозорість усіх судових рішень і слідчих дій, а з іншого боку, захист персональних даних і будь-якої інформації, яка може завдати шкоди людині у разі оприлюднення. Тому кожна держава (або союз держав) вирішує це питання по-своєму. І цей вибір, часто, визначає всю політику та економіку на найближчі десятиліття.
Підписуйтесь на Telegram-канал Trends і будьте в курсі актуальних трендів і прогнозів щодо майбутнього технологій, економіки, освіти та інновацій.